- Dataset metadata
- Schema structure
- Data lineage
- Dashboard and pipeline dependencies
- Business glossary and governance information
Accessing DataHub
DataHub provides a web-based interface that allows you to browse datasets, view lineage, and manage metadata. You can access it through a standard web browser.Accessing the UI
DataHub is available at the following designated URL:When you purchase NexusOne, you receive a client name.
Replace
client with your assigned client name.Authentication and authorization
DataHub supports multiple authentication mechanisms, such as:- Single Sign-On (SSO)
- OAuth 2.0 or OpenID Connect
- Viewer: Read-only access to datasets, lineage, and documentation
- Editor: Read and write access to update descriptions, add tags, and modify owners
- Admin: Authority over all actions, such as ingestion pipelines, glossary terms, and policies
Browsing and discovering assets
Assets represent items such as datasets, dashboards, pipelines, or domains. DataHub indexes these assets and records who owns them, how they connect to other assets, applied tags, and documentation.Searching for assets
You can search across all metadata types from the main search bar, such as:- Exact names or partial names, for example
sales_dailyorsales - Column names, for example,
customer_id - Tags or glossary terms
- The name of a task or pipeline that produces or transforms a dataset
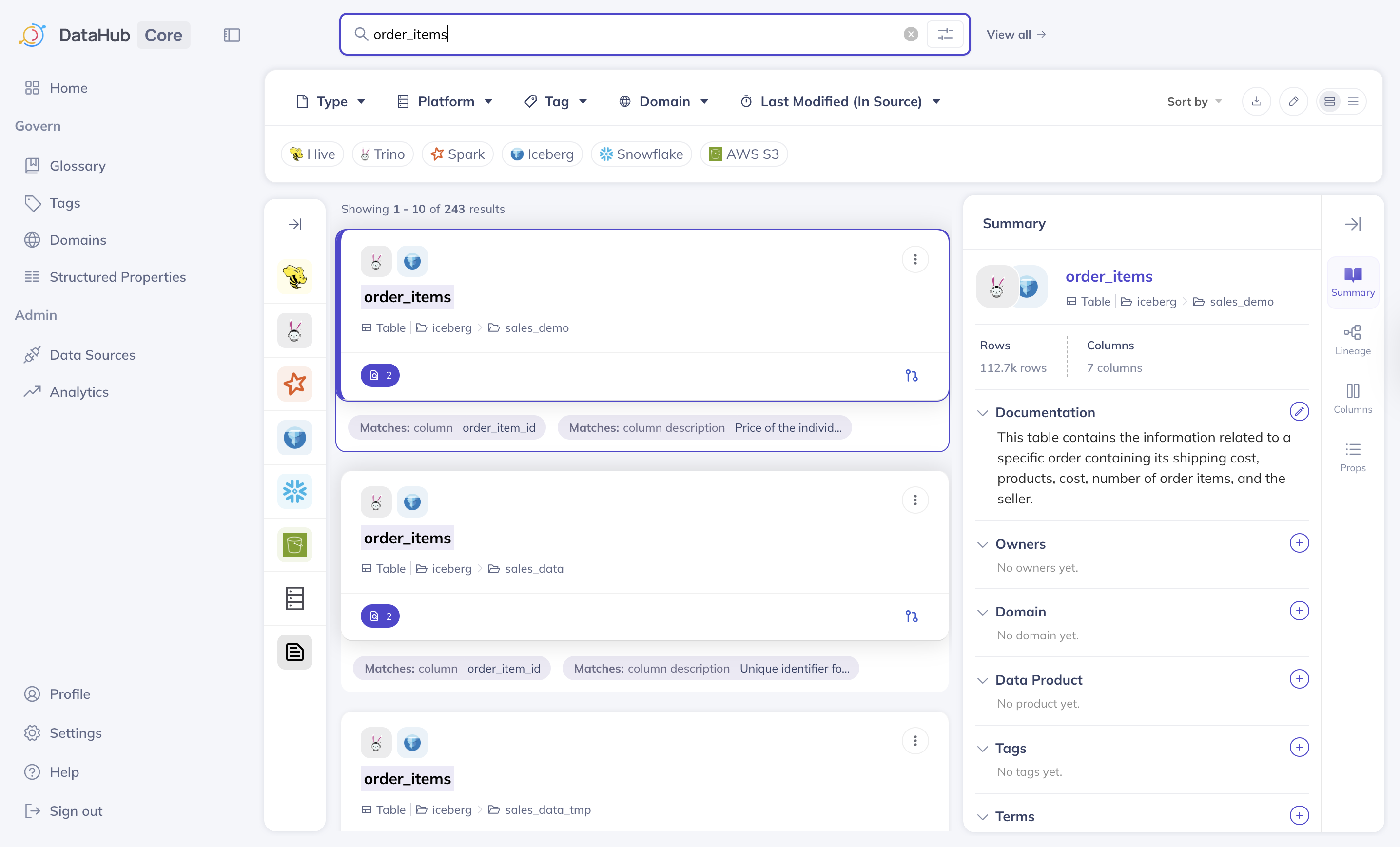
Searching for an asset
- Platforms: Spark, Airflow, Hive/Iceberg, Trino, or Superset
- Domains: Sales, Marketing, Finance, or Operations
- Tags: PII, Sensitive, or Analytics
Dataset overview page
Opening a dataset displays an overview page with several tabs containing details of the metadata. Some of these include:Columns: Column names, data types, descriptionsDescription: Purpose and usage notesOwners: Responsible team or usersTags: Labels that classify or categorize the datasetLineage: Upstream and downstream graphProperties: Storage location and system-specific detailsData Preview: If enabled, it displays sample rows for quick inspection
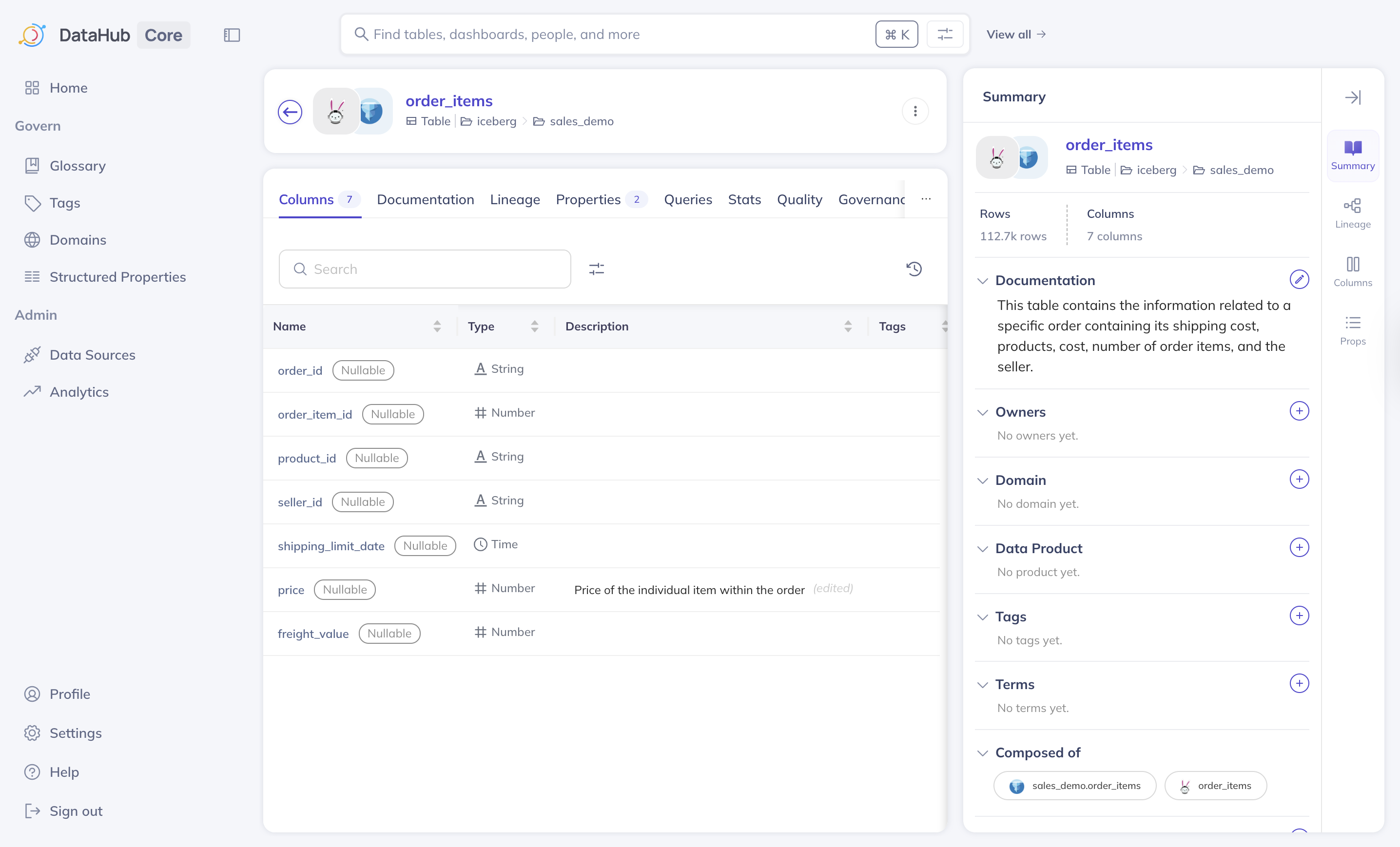
A dataset overview page
Metadata details
The Metadata details page provides a comprehensive view of a dataset’s technical, business, and operational metadata. It’s the central place where you can understand what a dataset contains, how it’s used, where it came from, and who is responsible for it.Dataset metadata summary
The summary sidebar provides a high-level summary of a dataset, so you can quickly determine its purpose and context.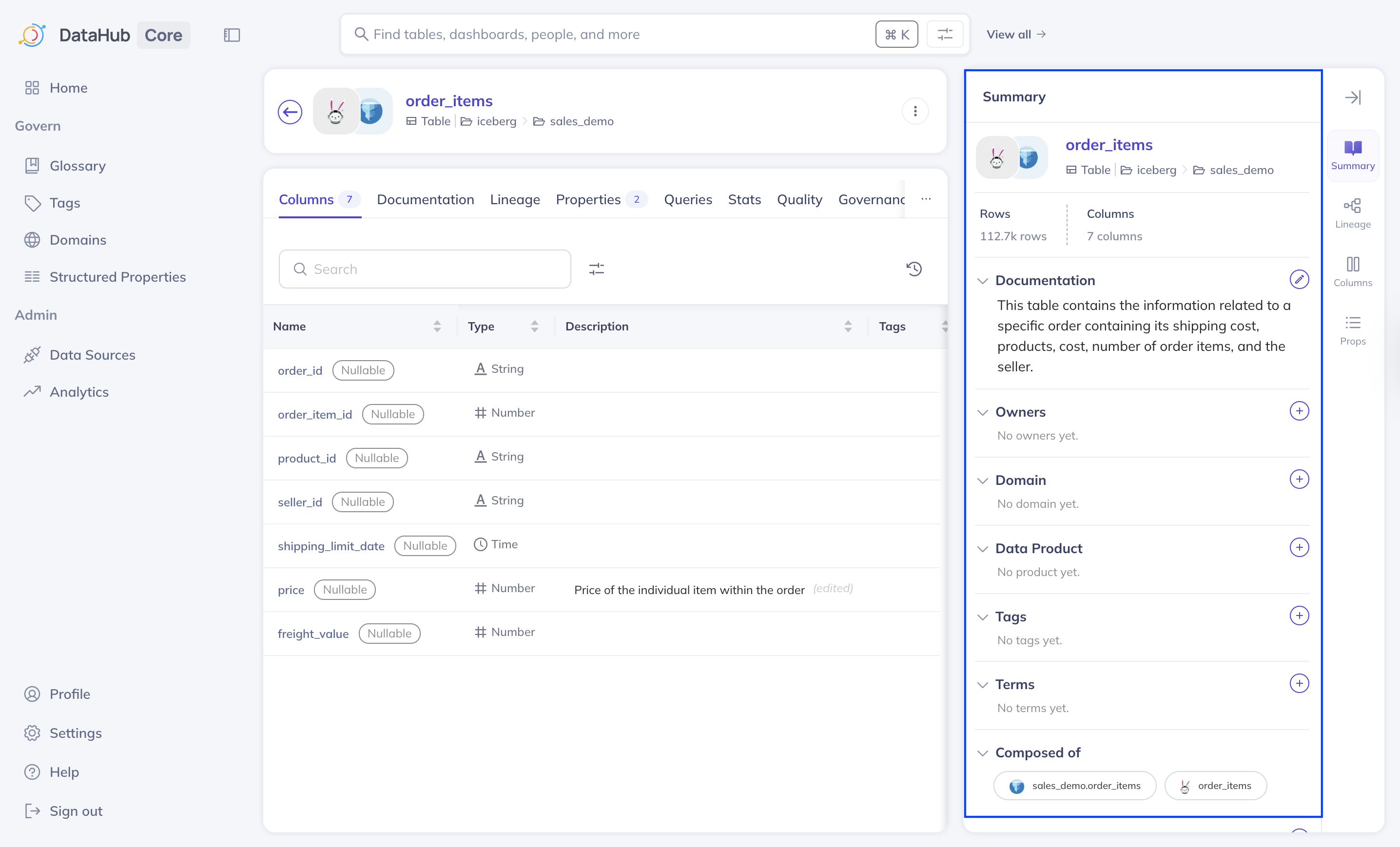
A dataset metadata summary
Documentation: Human-readable explanation of what the dataset containsOwners: Person or team responsible for maintaining the datasetDomain: Organizational unit or functional area the dataset belongs to, such as Finance, Marketing, or EngineeringData Product: Data managed by a domainTags: Informational labels such as PII, Finance, Sensitive, or AnalyticsComposed of: Platform-specific representation of the dataset, such as Iceberg, or TrinoStatus: Timestamp indicating when someone last modified the metadata
Schema detail
The table that appears when you open a dataset describes a schema detail, as previously described. However, the focus is on the schema in the “Columns” tab. Understanding the schema helps you know what data exists, how to use it, and how to interpret it correctly.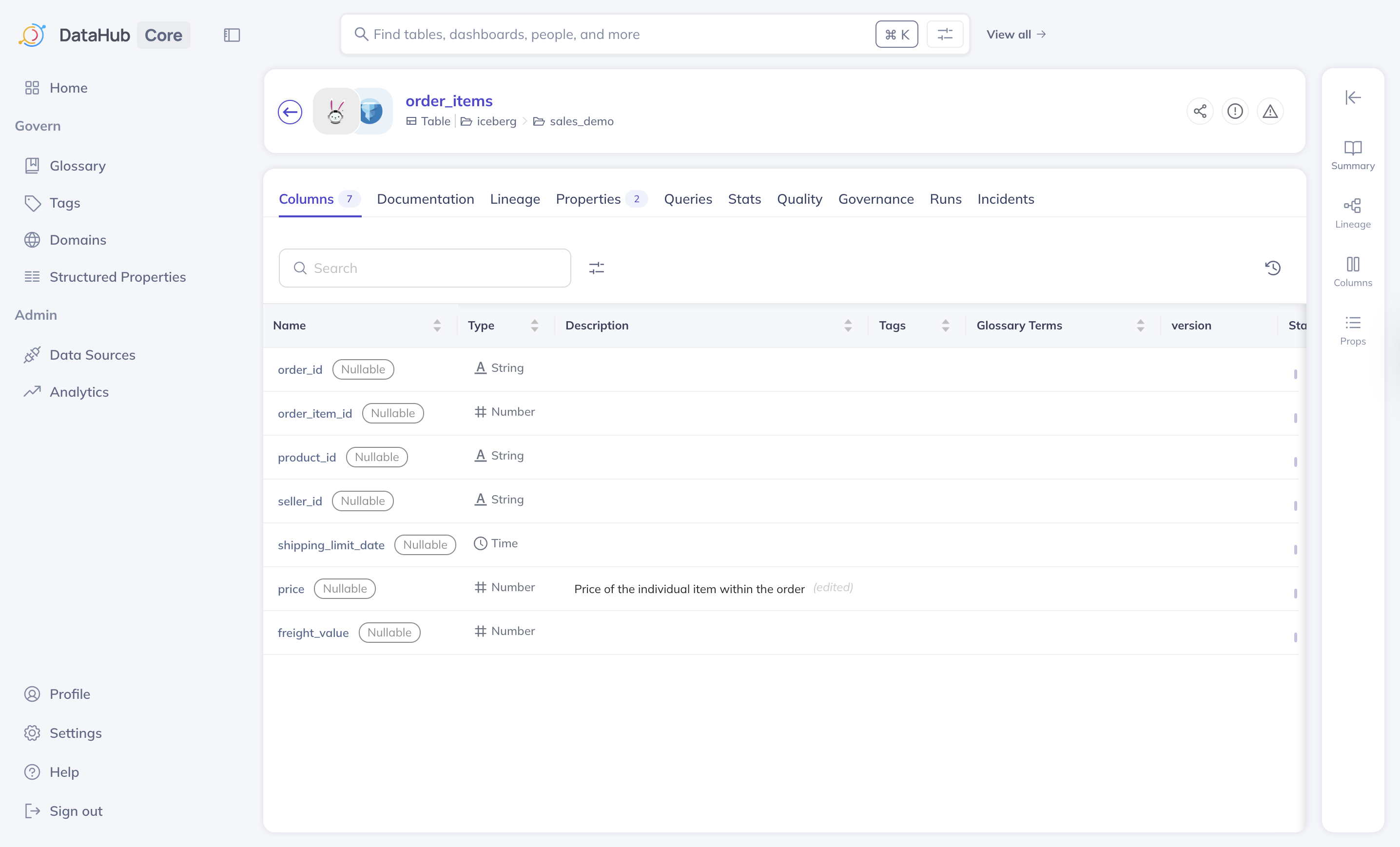
A dataset metadata summary
- Column name
- Data types such as
STRING,INTEGER, orTIMESTAMP - Business-friendly description containing meanings or definitions
- Tags containing labels for classification
Lineage details
The Lineage tab reveals what produced a dataset and which systems consume it. With this, you can identify dependencies, evaluate the impact of changes, and trace issues back to their origin. Two types of lineage exist on DataHub: dataset and job lineage.Dataset lineage
Dataset-level lineage displays a schema and its table.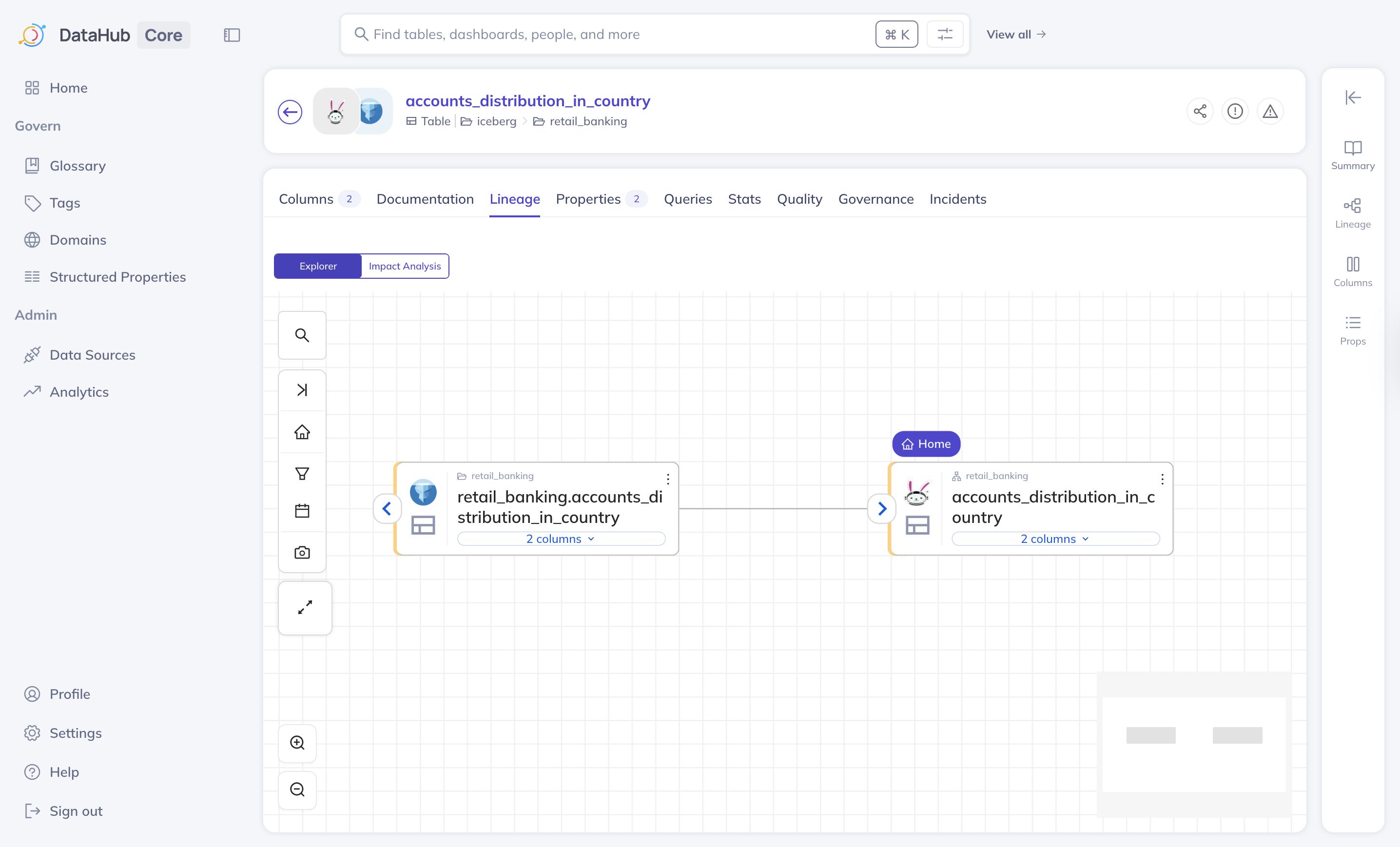
A dataset lineage
- Search for the dataset name, schema, or other identifiers indexed in DataHub.
- Open the dataset overview page and select the Lineage tab.
Job lineage
Job lineage displays the dataset lineage, along with the task or pipeline that produced or transformed it. Some of the supported tasks or pipelines include:- Spark jobs, such as batch or streaming
- Airflow DAGs and task-level lineage
- SQL-based ETL jobs such as Trino or dbt
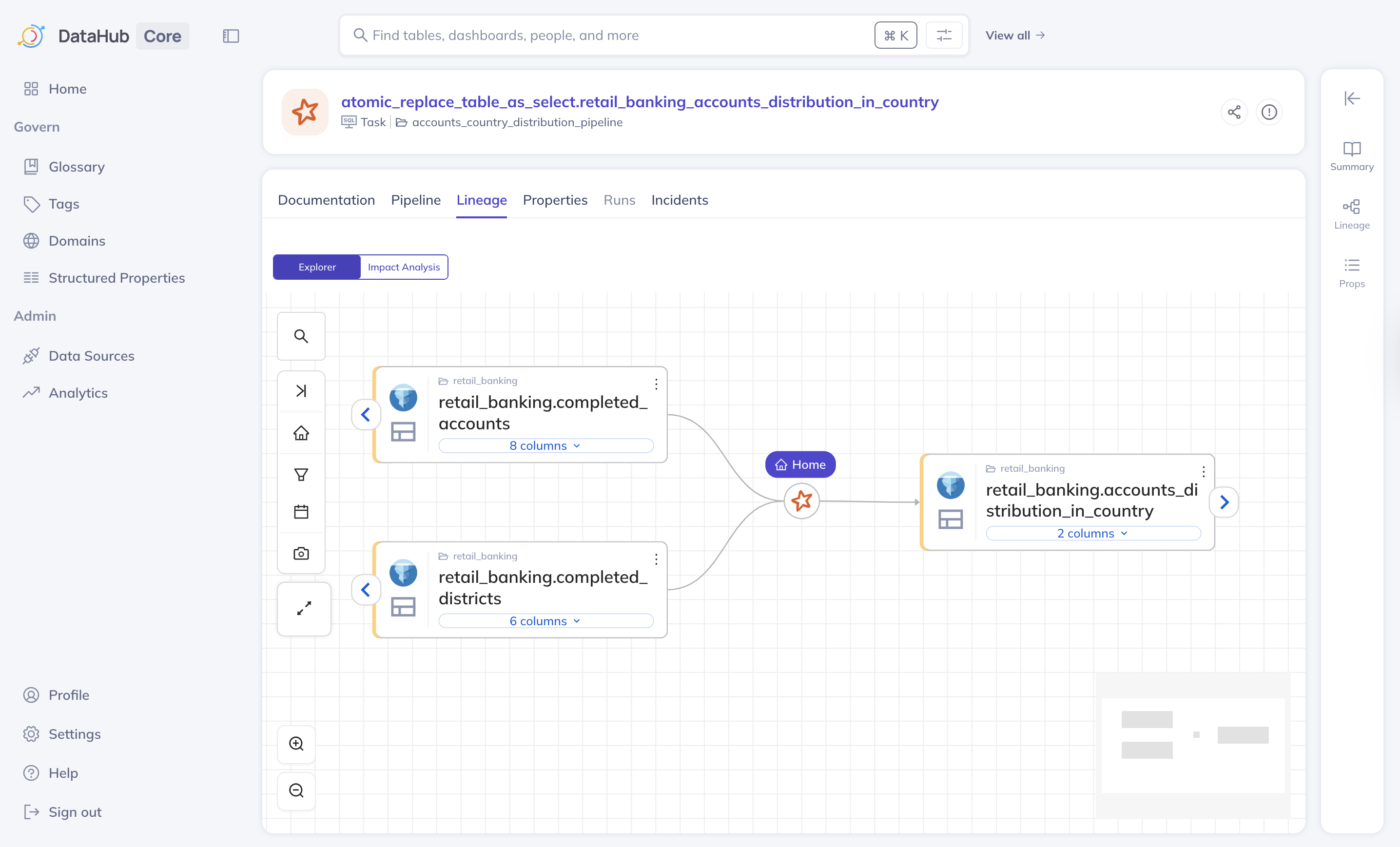
A job lineage
- Search for the job or pipeline name.
- Open the job overview page and select the Lineage tab.
API usage
DataHub provides REST and GraphQL APIs for programmatic metadata updates. These APIs are typically used for automated metadata pipelines, CI/CD workflows, or custom integrations where you need to update metadata without using the UI.REST API
The REST API supports creating, updating, and querying metadata by sending Metadata Change Events (MCE) or Metadata Aspects. An MCE is a message that describes changes to one or more assets. A Metadata Aspect is a specific piece of metadata about an asset, such as its ownership, tags, or schema. For example, update a dataset description.client with your client’s name.
The previous command does the following:
- Targets a dataset entity
- Updates the
datasetPropertiesaspect - Replaces the description with the provided text
GraphQL API
The GraphQL API provides a flexible interface for querying metadata and performing fine-grained updates. Use cases include:- Fetching lineage, schema, or ownership programmatically
- Adding tags or ownership to datasets
- Automating glossary term assignments
client with your client’s name.
The previous command does the following:
- Requests data profiles for the dataset
retail_banking.completed_accountsin thePRODenvironment - Attempts to retrieve: row count, column count, dataset size, and more
When to use APIs
Use API-based updates when you are trying to achieve the following:- Integrate DataHub with external systems
- Automate updates via pipelines using Airflow, Jenkins, or GitHub Actions
- Enforce metadata standards programmatically
- Bulk update metadata at scale
Data quality
DataHub provides capabilities for capturing, monitoring, and visualizing data quality rules and test results across datasets. These rules ensure that you can trust the data consumed and quickly identify issues affecting downstream products, models, or dashboards.Data quality details
When viewing the data quality of a dataset, DataHub displays the following:- List of all assertions/tests containing automated rules that validate the correctness of data
- Test results containing pass/fail status with run timestamps
- Timestamp of the latest execution
- Column-level and table-level checks
- Integrated external testing tools such as custom Spark jobs, or checks in Airflow jobs
- Associated tags
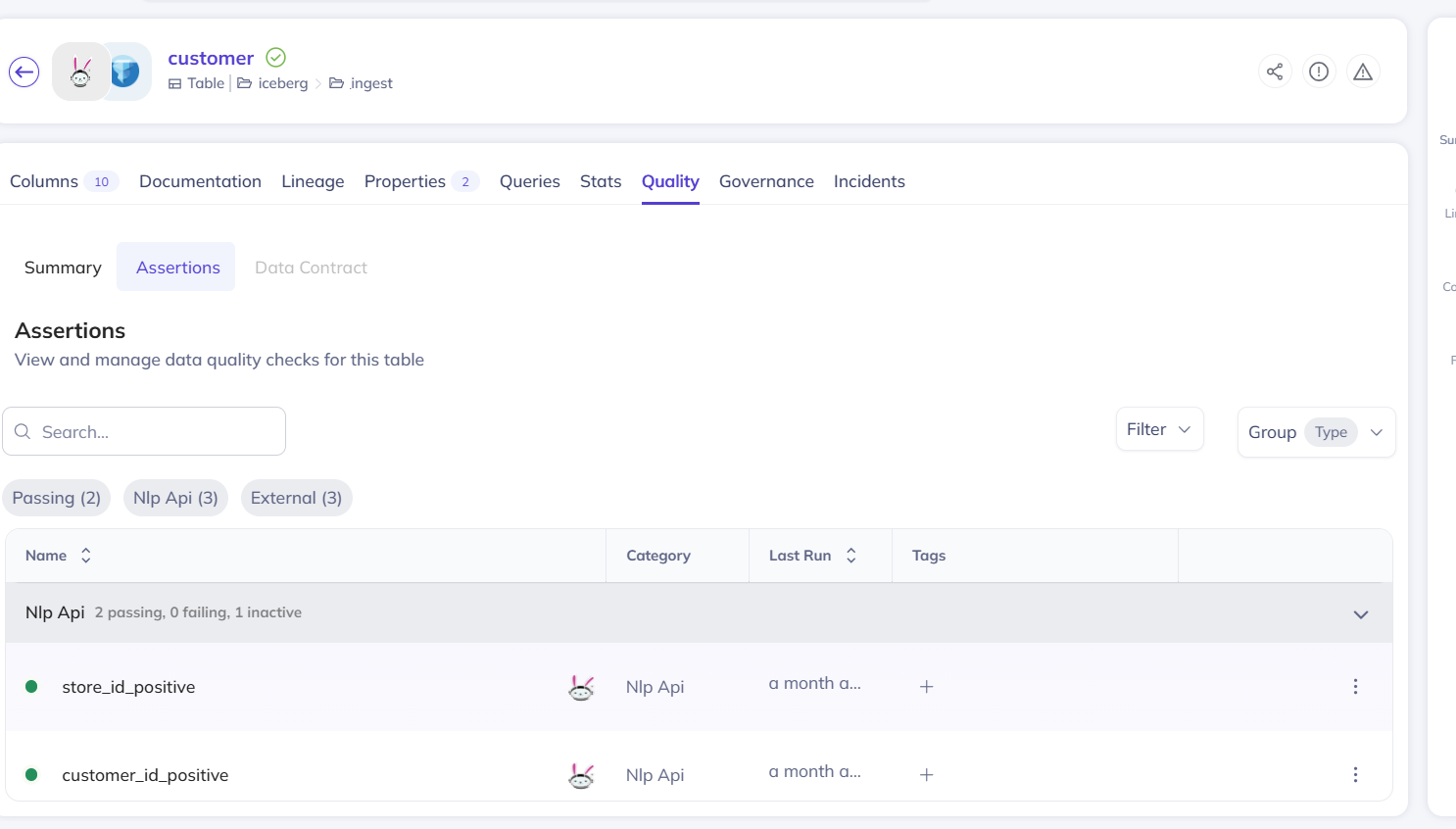
Data quality details
- Full assertion definition
- Historical pass/fail graph
- Execution logs or failure summaries
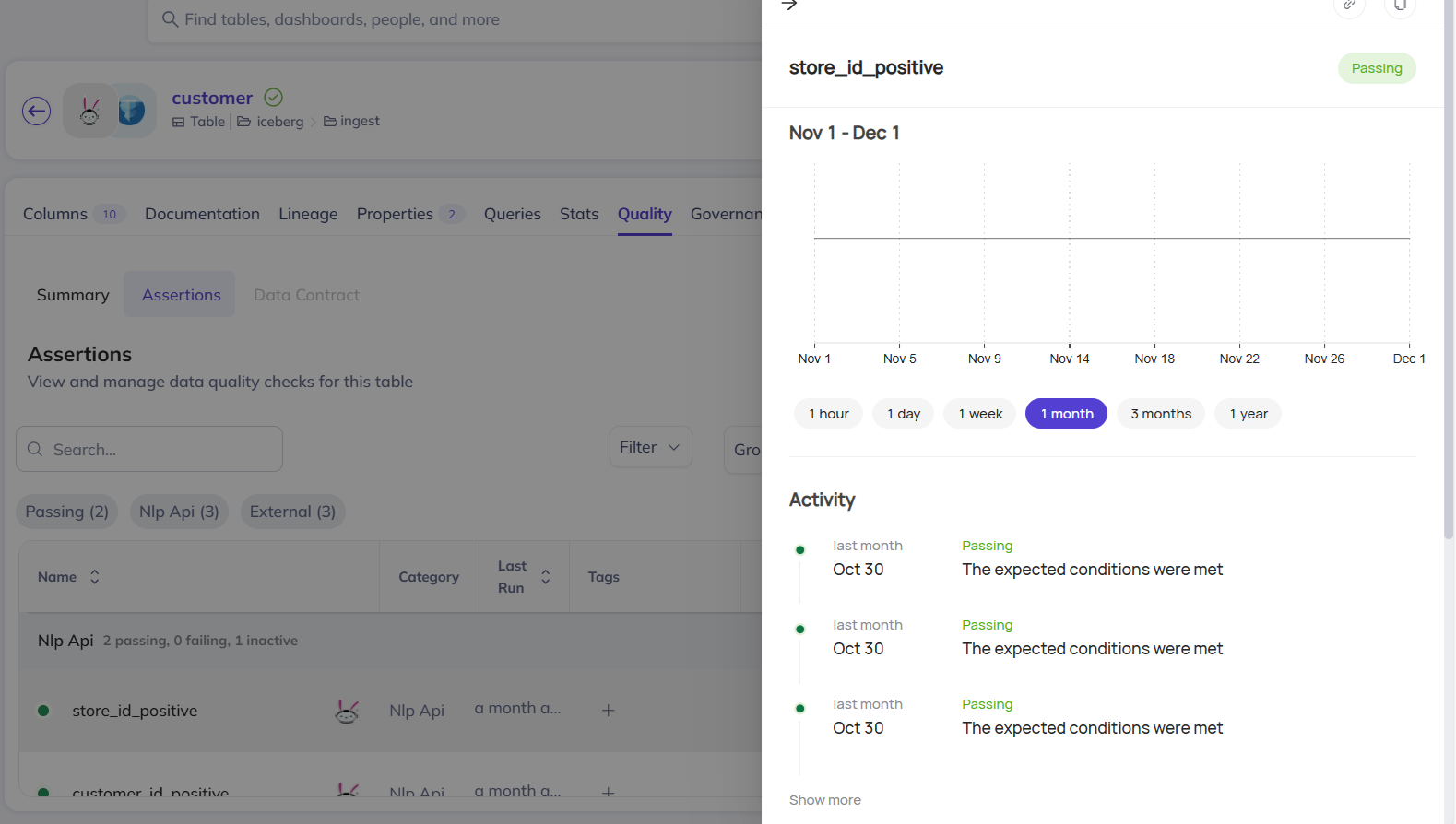
Details about a successful passing assertion
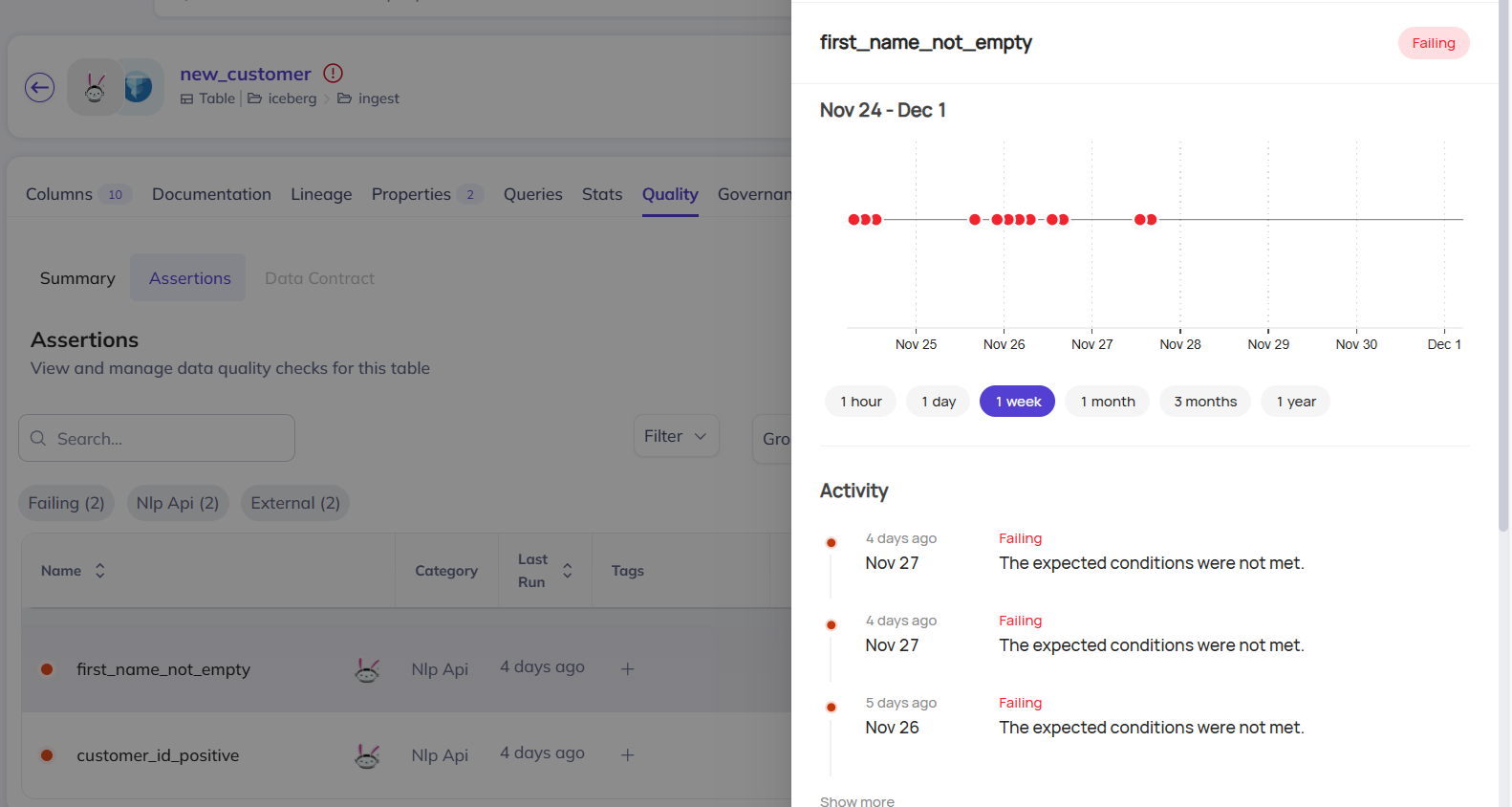
Details about a failing assertion
Data quality ingestion
Data quality metadata is typically ingested through scheduled pipelines. Supported integrations in NX1 include:- Custom Spark or SQL scripts sending results through the API
- Airflow DAGs producing test assertions
- Other integrations that can create assertions and send the results using the DataHub API
Troubleshooting data quality issues
When a test is failing, perform the following sequence of actions:- Search for the dataset name.
- Open the dataset overview page and select the Quality tab.
- Identify the failed assertion.
- Review the failure summary and logs.
- Use the Lineage tab to identify the root cause of the issue Ask yourself, “Is it an upstream table, or an upstream job?.”
- Contact the dataset owners or pipeline owners.
- Address the issue by either fixing the schema, repairing upstream data, or adjusting the transformation logic.
- Re-run the test and confirm that it passes.
Additional resources
- To learn about best practices when using DataHub, refer to the DataHub best practices page.
- For more details about DataHub, refer to the DataHub official documentation.
- If you are using the NexusOne portal and want to learn how to launch DataHub, refer to the Govern page.